

n8n이란 무엇인가?
n8n을 처음 보면 뭔가 쉬워 보이면서도 어렵다.
화면에는 노드가 있고, 선으로 이어 붙이면 자동화가 되는 것처럼 보인다.
그래서 처음에는 “아, 이거 그냥 블록 몇 개 연결하면 되는 거 아닌가?” 싶다.
근데 막상 직접 무언가를 만들기 시작하면 생각보다 빨리 막힌다.
특히 단순히 Gmail 알림을 Slack으로 보내는 정도가 아니라, 여러 데이터를 가져오고, AI로 판단하고,
조건에 따라 버리고, 다시 합치고, 결과를 정리하는 식으로 가면 얘기가 달라진다.
나도 예전에 n8n으로 상품이나 키워드 후보를 찾는 자동화 흐름을 만들었다.
처음 구상은 단순했다.
해외 상품명이나 키워드를 가져오고,
AI가 한국식 검색어로 바꾸고,
위험한 품목은 걸러내고,
검색량이나 쇼핑 데이터를 붙이고,
점수를 매긴 다음,
괜찮은 후보만 추려내는 흐름.
말로 쓰면 꽤 그럴듯하다.
문제는 이걸 실제 n8n 노드로 만들면, 중간에 데이터가 어디서 몇 개로 나뉘고 어디서 다시 합쳐지는지가 금방 복잡해진다는 점이다.
n8n은 결국 노드를 이어 붙이는 도구다
n8n은 업무자동화 도구다.
조금 더 정확히 말하면, 여러 서비스나 API, 데이터 처리 단계를 노드 단위로 연결해서 하나의 자동화 흐름을 만드는 도구에 가깝다.
예를 들어 이런 식이다.
특정 시간이 되면 실행된다.
외부 API에서 데이터를 가져온다.
그 데이터를 필요한 형태로 바꾼다.
조건에 맞는 것만 통과시킨다.
결과를 구글 시트나 데이터베이스에 저장한다.
필요하면 Slack이나 이메일로 알림을 보낸다.
이런 각각의 단계를 n8n에서는 노드로 만든다.
그리고 노드와 노드를 선으로 연결하면 하나의 워크플로우가 된다.

여기까지만 보면 꽤 직관적이다.
엑셀 함수나 파이썬 코드보다 훨씬 눈에 잘 보이기도 한다.
하지만 n8n을 “코딩 없이 다 되는 도구” 정도로 생각하면 금방 실망할 수 있다.
노드를 연결하는 건 쉽지만, 데이터가 어떤 형태로 들어오고 나가는지 이해하는 건 별개의 문제다.
실제로 막히는 건 노드 연결보다 데이터 흐름이다
n8n에서 처음 헷갈리는 지점은 노드 자체가 아니다.
진짜 어려운 건 데이터 흐름이다.
예를 들어 상품 후보 100개가 들어왔다고 해보자.
AI 필터를 거쳐서 60개만 남을 수 있다.
그중 일부는 검색량 조회에 실패할 수 있다.
또 어떤 노드는 item을 하나씩 처리하고, 어떤 노드는 전체를 한 번에 묶어서 처리한다.
이때 뒤쪽에서 Merge를 잘못 쓰면 결과 개수가 이상해진다.
Loop 안에서 처리한 결과가 바깥으로 제대로 모이지 않을 수도 있다.
IF 분기에서 KEEP만 통과시킨 줄 알았는데, 나중에 보니 실패 데이터가 섞여 있기도 하다.
내가 만들던 키워드 발굴 자동화에서도 이런 문제가 계속 나왔다.
AI가 KEEP이라고 판단한 것만 뒤로 보내고 싶은데, 중간에 결과 취합 위치가 애매해지면 뒤쪽 노드에서 개수가 맞지 않는다.
버킷별로 후보를 나누고 다시 선별하려고 하면, “지금 이 데이터가 원본 기준인지, 필터 후 기준인지, 루프 안의 일부인지”를 계속 확인해야 한다.

이게 n8n의 현실적인 어려움이다.
겉으로는 노코드 자동화 도구지만, 어느 정도 복잡해지는 순간 데이터 구조를 이해해야 한다.
그래도 n8n이 좋은 이유
그럼에도 n8n이 괜찮은 이유는 분명하다.
첫째, 흐름이 눈에 보인다.
파이썬 코드로만 만들면 전체 로직이 머릿속에 있어야 하는데, n8n은 노드가 화면에 보인다.
어디서 데이터를 가져오고, 어디서 AI 판단을 하고, 어디서 걸러내는지 시각적으로 확인하기 좋다.
둘째, 외부 서비스 연결이 편하다.
Gmail, Google Sheets, Slack, Notion, HTTP Request 같은 기본 연결이 준비되어 있다.
특히 API를 하나씩 직접 코드로 붙이는 것보다, n8n에서 HTTP Request 노드로 먼저 테스트해보는 게 더 빠를 때가 많다.
셋째, 실험하기 좋다.
아직 사업 아이디어가 확정되지 않았거나, 자동화 흐름이 자주 바뀌는 단계라면 코드로 전부 짜는 것보다 n8n에서 노드로 바꿔보는 게 편하다.
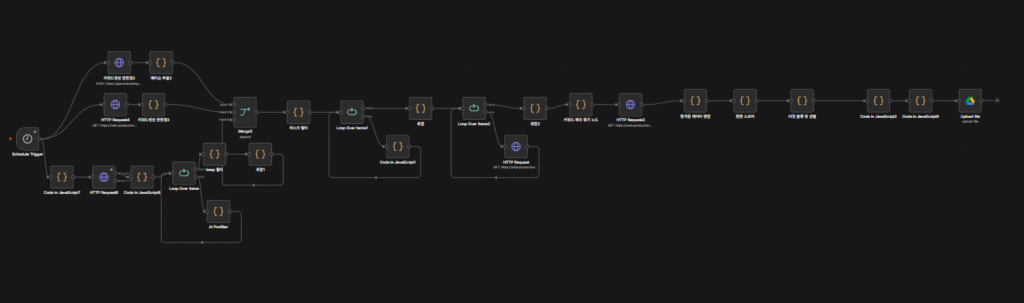
(위 이미지는 아마존에서 수집한 키워드를 네이버 API로 분석한뒤 생성하는 상품발굴 로직이다.)
다만 이 장점은 “작고 명확한 흐름”일 때 잘 살아난다.
처음부터 거대한 자동화를 만들면 장점보다 복잡함이 먼저 튀어나온다.
처음부터 큰 자동화를 만들면 거의 반드시 꼬인다
n8n을 처음 쓸 때 가장 조심해야 할 건 욕심이다.
예를 들어 “상품 발굴 자동화를 만들자”라고 하면 범위가 너무 넓다.
상품 데이터 수집, 키워드 변환, 리스크 필터링, 검색량 조회, 가격 비교, 점수화, 보고서 생성까지 전부 들어간다.
이걸 한 번에 만들려고 하면 거의 반드시 꼬인다.
차라리 처음에는 한 단계만 보는 게 낫다.
예를 들어:
해외 상품명 10개를 입력한다.
AI가 한국식 키워드로 바꾼다.
결과를 구글 시트에 저장한다.
이 정도만 먼저 만들어도 된다.
그 다음에 리스크 필터를 붙이고, 그 다음에 검색량 조회를 붙이고, 그 다음에 점수화를 붙이는 식으로 가야 한다.

자동화는 한 번에 완성하는 것보다, 작은 흐름을 안정적으로 붙여나가는 쪽이 낫다.
특히 n8n은 노드가 늘어날수록 보기에는 화려해지지만, 디버깅은 더 어려워진다.
n8n과 파이썬은 경쟁 관계가 아니다
n8n을 쓰다 보면 결국 이런 생각도 든다.
“이거 그냥 파이썬으로 짜는 게 낫지 않나?”
어느 정도 맞는 말이다.
반복 로직이 많고, 데이터 처리 규칙이 복잡하고, 결과를 세밀하게 통제해야 한다면 파이썬이 더 편할 수 있다.
반대로 여러 웹 서비스를 연결하고, 중간중간 사람이 결과를 확인하고, 빠르게 실험하는 단계라면 n8n이 편하다.
그러니까 둘 중 하나만 고를 문제는 아니다.
n8n은 흐름을 빠르게 실험하는 데 좋고,
파이썬은 복잡한 데이터 처리나 안정적인 실행에 좋다.
실제로 자동화 시스템을 만들다 보면 둘을 섞는 방식이 더 현실적일 수 있다.
n8n이 전체 흐름을 관리하고, 복잡한 분석이나 가공은 파이썬 스크립트나 API로 넘기는 식이다.
정리
n8n은 자동화를 쉽게 만들어주는 도구이긴 하지만, 모든 걸 쉽게 만들어주는 도구는 아니다.
단순한 알림 자동화나 시트 정리 정도는 꽤 직관적으로 만들 수 있다.
하지만 상품 키워드 발굴처럼 여러 API, AI 판단, 조건 분기, 루프, 병합이 들어가는 순간부터는 데이터 흐름을 이해해야 한다.
그래서 n8n을 처음 시작한다면 큰 자동화부터 만들 필요는 없다.
입력 하나, 처리 하나, 저장 하나.
이 정도의 작은 흐름부터 만드는 게 낫다.
그 작은 흐름이 제대로 돌아가면, 그때 조건 분기나 AI 판단을 붙이면 된다.
n8n은 거대한 자동화 시스템을 한 번에 만드는 도구라기보다, 반복되는 업무 흐름을 눈에 보이게 쪼개고 하나씩 연결해보는 도구에 가깝다.

Great content! Keep up the good work!